loki与alertmanager集成实现告警推送到企业微信
loki与alertmanager集成实现告警推送到企业微信
参考:
- https://blog.51cto.com/u_13858192/2776101
- https://blog.51cto.com/u_13858192/2776101
- https://grafana.com/docs/loki/latest/alert/#rules-and-the-ruler
- 其他文件 已及详细部署 >> 传送门
一. docker-compose.yml文件处loki与alertmanager配置
此目录配置统一存放于
/opt/loki目录宿主机创建告警挂载目录 (
/opt/loki/rules/fake)1
2# 创建报警文件挂载目录
mkdir -p /opt/loki && cd /opt/loki && mkdir -p ./rules/fakedocker-compose.yml文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67version: "3"
services:
loki:
container_name: loki
image: grafana/loki:2.4.0
restart: always
ports:
- 3100:3100
volumes:
- ./loki-local-config.yaml:/etc/loki/loki-local-config.yaml
- ./rules/fake:/etc/loki/rules/fake # Loki告警规则存储路径yaml告警文件执行放入即可没有限制条件
#- ./rules/rules-temp/fake:/etc/loki/rules-temp/fake # 为rules临时规则 存储目录
- /etc/localtime:/etc/localtime
command: -config.file=/etc/loki/loki-local-config.yaml # -target=ruler
networks:
- loki
promtail:
container_name: promtail
image: grafana/promtail:2.4.0
restart: always
depends_on:
- loki
volumes:
- /var/log:/var/log
- ./promtail-local-config.yaml:/etc/promtail/promtail-local-config.yaml
- /etc/localtime:/etc/localtime
command: -config.file=/etc/promtail/promtail-local-config.yaml
networks:
- loki
alertmanager:
image: prom/alertmanager:latest
restart: always
container_name: alertmanager
hostname: alertmanager
ports:
- 9093:9093
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml # 企业微信告警模板
- ./wechat.tmpl:/etc/alertmanager/wechat.tmpl # 发送消息模板
- ./alertmanager/data:/alertmanager/data # 数据存放目录持久化
command:
- --config.file=/etc/alertmanager/alertmanager.yml
networks:
- loki
grafana:
container_name: grafana
image: grafana/grafana:8.5.0
restart: always
depends_on:
- loki
- promtail
ports:
- 3000:3000
volumes:
# - grafana-storage:/var/lib/grafana (可选)
# - ./grafana.ini:/etc/grafana/grafana.ini (可选)
- /etc/localtime:/etc/localtime
networks:
- loki
networks:
loki:
driver: bridge
二. alertmanager配置
alertmanager.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
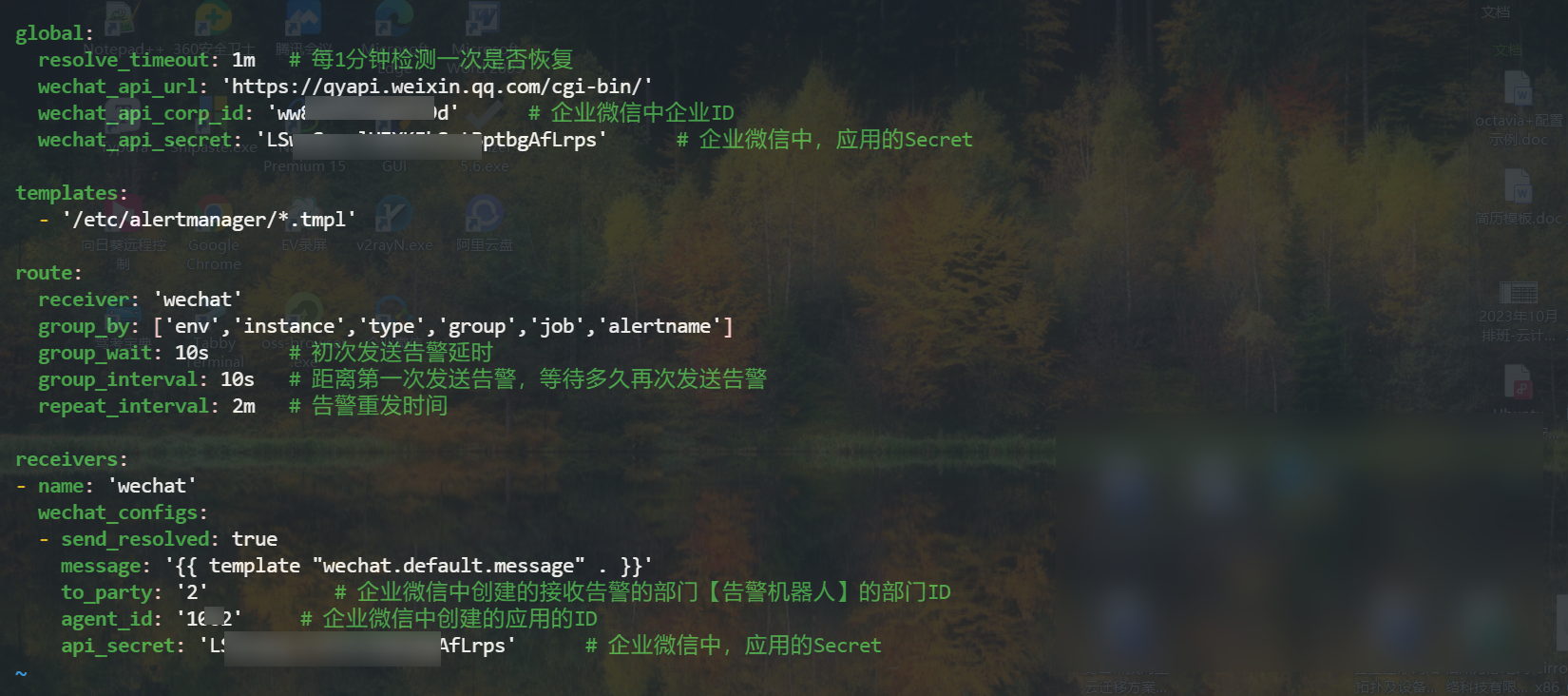
24global:
resolve_timeout: 1m # 每1分钟检测一次是否恢复
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_corp_id: 'ww83d9d' # 企业微信中企业ID
wechat_api_secret: 'LSwofLrps' # 企业微信中,应用的Secret
templates:
- '/etc/alertmanager/*.tmpl'
route:
receiver: 'wechat'
group_by: ['env','instance','type','group','job','alertname']
group_wait: 10s # 初次发送告警延时
group_interval: 10s # 距离第一次发送告警,等待多久再次发送告警
repeat_interval: 2m # 告警重发时间
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '2' # 企业微信中创建的接收告警的部门【告警机器人】的部门ID
agent_id: '10000002' # 企业微信中创建的应用的ID
api_secret: 'LgAfLrps' # 企业微信中,应用的Secret
wechat.tmpl1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
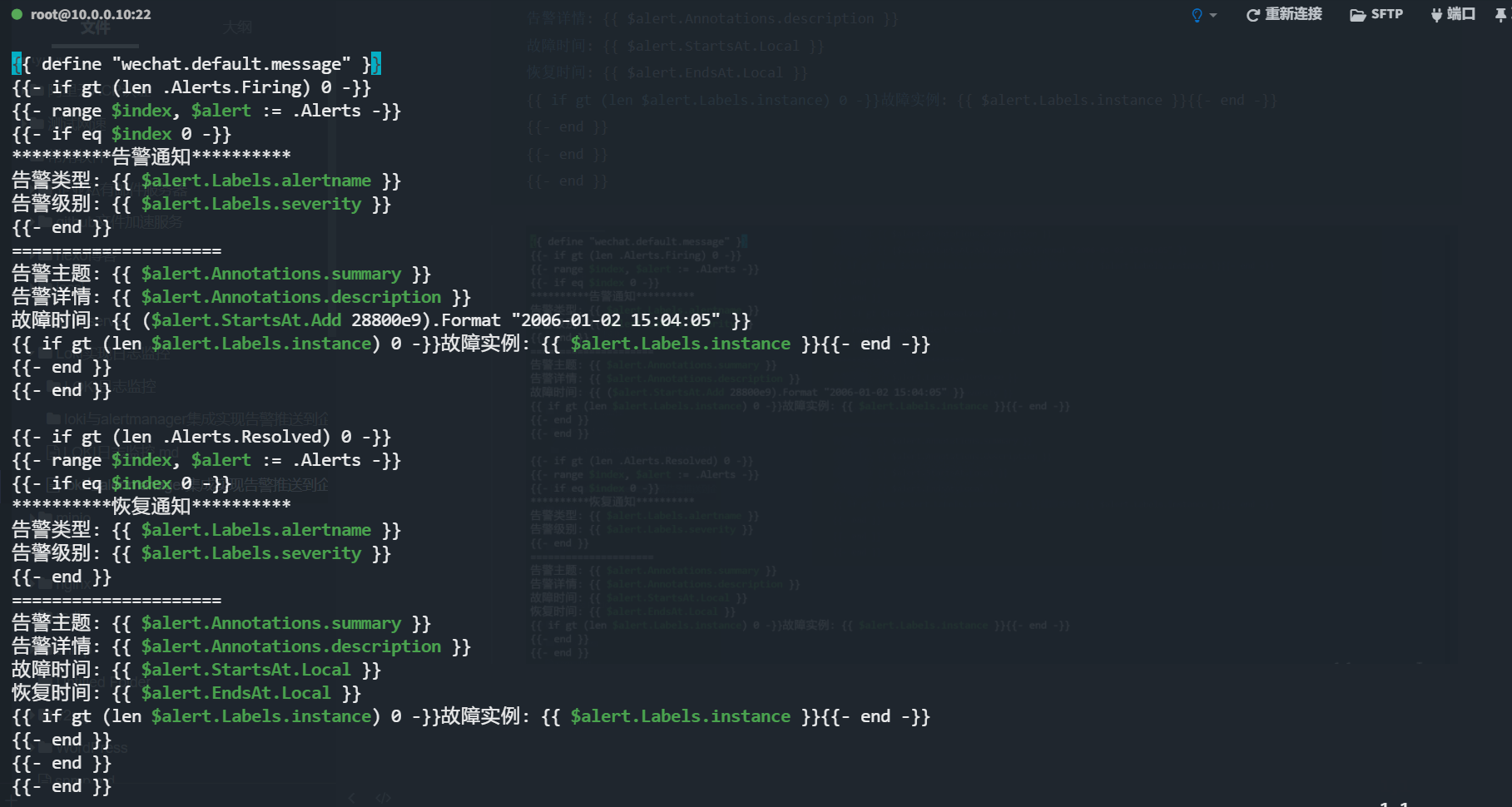
31{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********告警通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********恢复通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
恢复时间: {{ $alert.EndsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- end }}
三. loki loki-local-config.yaml配置
loki-local-config.yaml文件末尾添加告警配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 末尾增加此段配置即可
# rules规则存储
# 主要支持本地存储(local)和对象文件系统(azure, gcs, s3, swift)
ruler:
storage:
type: local
local:
directory: /etc/loki/rules # Loki告警规则存储路径
rule_path: /etc/loki/rules-temp
alertmanager_url: http://10.0.0.10:9093 # alertmanager地址和端口
ring:
kvstore:
store: inmemory
enable_api: true
# enable_alertmanager_v2: truepromtail配置监控日志1
2
3
4
5
6
7
8# apt日志 构建完成后使用apt安装一个软件 用于测试是否成功采集到日志
- job_name: test
static_configs:
- targets:
- localhost
labels:
job: test
__path__: /var/log/apt/*.log
四. 告警文件留存
1.用法概览:
测试告警规则文件留存目录(
/opt/loki/rules/fake)此监控日志程序相当SB苦于没有其他开源的不然断然不会使用
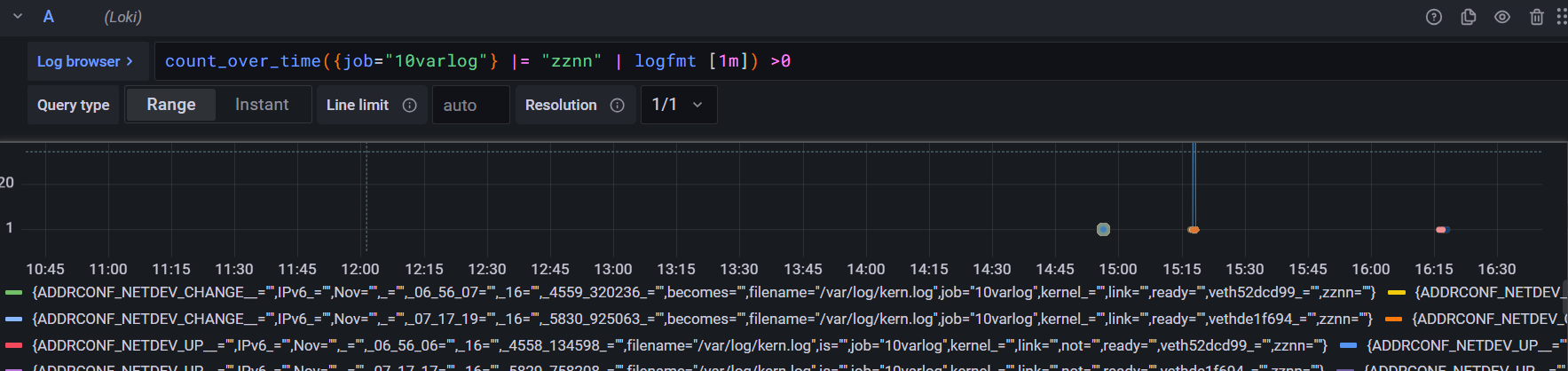
logql查询关键词{job="10varlog"} |= "zznn" | logfmt语句配合聚合函数可写为
1
2
3
4# 查询关键字
{job="10varlog"} |= "zznn" | logfmt
# 配合聚合函数写为
count_over_time({job="10varlog"} |= "zznn" | logfmt [1m]) >0聚合函数集成:
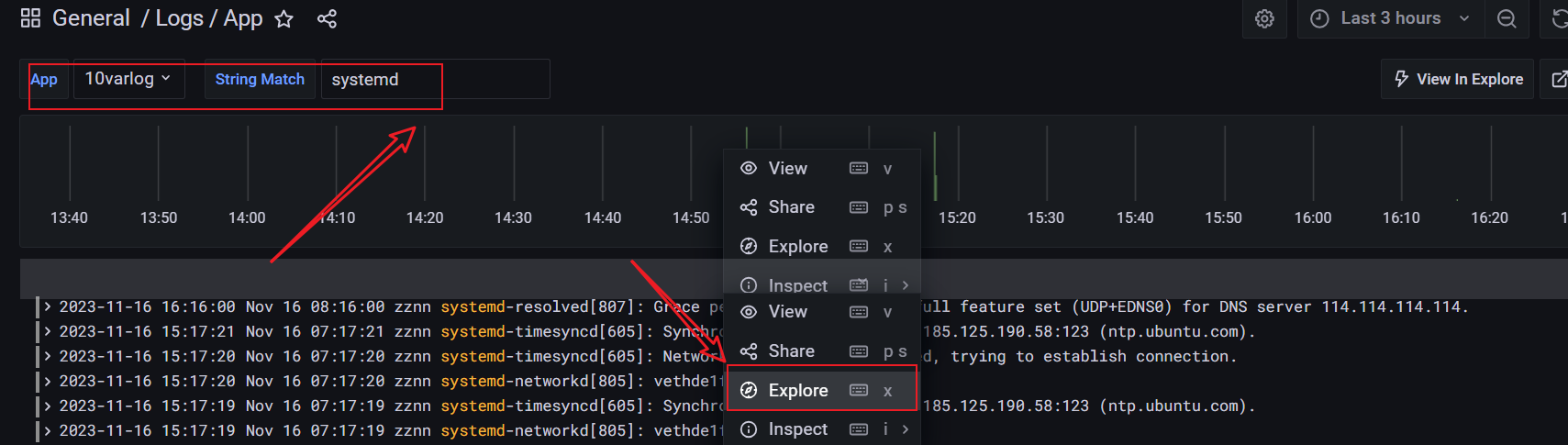
如果不知道怎么写可以先导入
13639 dashboard面板使用面板查询处后切换到exploter查看语句Loki 的 rulers 规则和结构与 Prometheus 是完全兼容,唯一的区别在于查询语句(LogQL)不同,在Loki中我们用
LogQL写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16groups:
# 组名称
- name: xxxx
rules:
# Alert名称
- alert: xxxx
# logQL查询语句
expr: xxxx
# 产生告警的持续时间 pending.
[ for: | default = 0s ]
# 自定义告警事件的label
labels:
[ : ]
# 告警时间的注释
annotations:
[ : ]例:
sum(rate({app="nginx"} |= "error" [1m])) by (job) / sum(rate({app="nginx"}[1m])) by (job) > 0.01表示:通过日志查到 nginx 日志的错误率大于1%就触发告警,同样重新使用上面的 values 文件更新 Loki
例:通过日志查到某个业务日志的错误率大于5%就处罚告警,那么可以配置成这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14groups:
- name: should_fire
rules:
- alert: HighPercentageError
expr: |
sum(rate({app="foo", env="production"} |= "error" [5m])) by (job)
/
sum(rate({app="foo", env="production"}[5m])) by (job)
> 0.05
for: 10m
labels:
severity: page
annotations:
summary: High request latency对于有些应用的特殊的事件,我们也可以利用Loki的ruler来做相关的通知,比如检查日志中的base auth认证泄漏事件
1
2
3
4
5
6
7
8
9- name: credentials_leak
rules:
- alert: http-credentials-leaked
annotations:
message: "{{ $labels.job }} is leaking http basic auth credentials."
expr: 'sum by (cluster, job, pod) (count_over_time({namespace="prod"} |~ "http(s?)://(\\w+):(\\w+)@" [5m]) > 0)'
for: 10m
labels:
severity: critical

2.本教程留存部分
aler.yaml
1 | groups: |
election-log-alert.yml
1 | groups: |
大量报错日志
rate-alert.yml
1 | [root@db15 fake]# cat rate-alert.yml |
1 | [root@db01 promtail]# cat promtail-local-config.yml |
关键字error报错
1 | groups: |

五. 效果
日志最近五天的行数大于0就告警
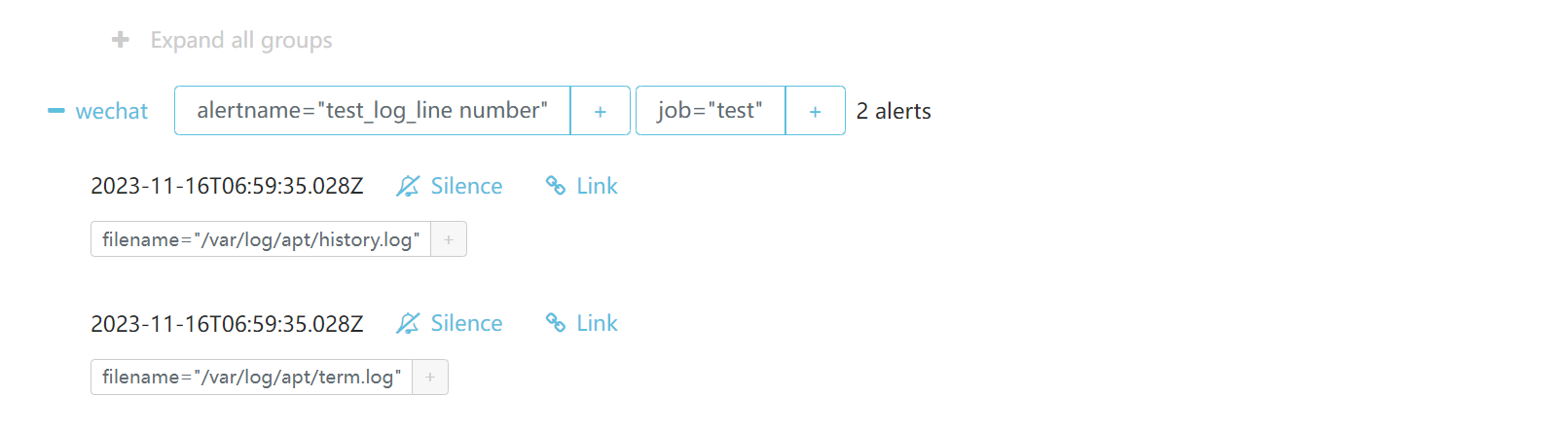
教程结束。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ZzNnWn!
- 微信
- 支付宝




评论






