osd数据均衡reweight-by-utilization / reweight-by-pg 及 balancer均衡osd数据参考:
https://docs.ceph.com/en/latest/rados/operations/upmap/ (官网)https://juejin.cn/post/6844903747521363976#heading-0 (掘金)https://www.cnblogs.com/dengchj/p/13898686.html (博客园)https://blog.csdn.net/ff_gogo/article/details/87981682 (csdn)
概览:
一. reweight-by-utilization/reweight-by-pg均衡数据 1. 查看数据分布是否均衡1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ ceph osd df tree root@ceph-1:~ //返回 ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS 0 hdd 0.01949 1.00000 20 GiB 3.9 GiB 3.6 GiB 32 KiB 338 MiB 16 GiB 19.45 0.98 225 up 1 hdd 0.01949 1.00000 20 GiB 4.0 GiB 3.6 GiB 27 KiB 434 MiB 16 GiB 19.93 1.01 225 up 2 hdd 0.01949 1.00000 20 GiB 4.0 GiB 3.6 GiB 27 KiB 430 MiB 16 GiB 19.90 1.01 225 up TOTAL 60 GiB 12 GiB 11 GiB 87 KiB 1.2 GiB 48 GiB 19.76 MIN/MAX VAR: 0.98/1.01 STDDEV: 0.22 ceph osd df tree | awk '/osd\./{print $NF" "$(NF-2)" "$(NF-4) }' root@ceph-1:~ //返回 osd_num PGS %USE osd.0 225 19.48 osd.1 225 19.93 osd.2 225 19.91
注: 可以看到osd编号 osd上分布发pg数 osd使用率
2. reweight-by-pg 按归置组分布情况调整 OSD 的权重 1 2 3 4 5 6 7 8 9 10 11 12 13 14 root@ceph-1:~ //返回 moved 0 / 675 (0%) avg 225 stddev 0 -> 0 (expected baseline 12.2474) min osd.0 with 225 -> 225 pgs (1 -> 1 * mean) max osd.0 with 225 -> 225 pgs (1 -> 1 * mean) oload 120 max_change 0.05 max_change_osds 4 average_utilization 11547.0634 overload_utilization 13856.4761 no change
当集群数据不均衡时执行调整 输出类似如下:
3. reweight-by-utilization 按利用率调整 OSD 的权重1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ceph osd reweight-by-utilization root@ceph-1:~ //返回 moved 0 / 675 (0%) avg 225 stddev 0 -> 0 (expected baseline 12.2474) min osd.0 with 225 -> 225 pgs (1 -> 1 * mean) max osd.0 with 225 -> 225 pgs (1 -> 1 * mean) oload 120 max_change 0.05 max_change_osds 4 average_utilization 0.1979 overload_utilization 0.2375 no change
当集群数据不均衡时执行调整 输出类似如下:
4. 数据均衡后还原权重1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ ceph osd df tree | awk '/osd\./{print $NF" "$4 }' osd_num REWEIGHT osd.0 1.00000 osd.1 1.00000 osd.2 1.00000 $ ceph osd reweight 5 1.0 ceph osd df tree | awk '/osd\./{print $NF}' ceph osd df tree | awk '/osd\./{print $NF}' |awk -F'[ .]+' '{print $2}' for i in `ceph osd df tree | awk '/osd\./{print $NF}' |awk -F'[ .]+' '{print $2}' `; do ceph osd reweight ${i} 1.0; done
二. balancer均衡osd数据 1.前言(此部分为原理梳理不执行)参考:
https://www.cnblogs.com/zphj1987/p/13575484.html https://ypdai.github.io/2020/07/30/osd%EF%BC%9Apg%E5%9D%87%E8%A1%A1%E5%B7%A5%E5%85%B7balancer/
在集群正式上线之前需要进行pg数以及pg分布的检查操作,如果pg数和pg分布不合理,需要进行调整。这样能够的提升整个集群资源的使用率,同时对集群整体的性能提升有一定帮助。下面介绍下如何使用mgr的balancer插件来调整pg分布平滑度。
支持两种模式它支持两种模式upmap和crush-compat
upmap :会强制重新映射特定pg.
crush-compat :通过改变crush weight来调整pg分布,最终实现数据均衡。
两种模式的实现原理
crush-compat: 实现原理是通过更改crush weigth来调整权重 实现pg的均衡 执行命令的数据迁移过程,相应pg会处于active+remapped+backfill状态,pg重新映射且数据回填之中 内部osd之间数据的读写过程,并不会影响客户端的读写操作。upmap: 以pg单位重新映射特定的pg到特定的osd,实现方法是将更新的pg映射关系添加到osdmap中,以此实现对PG映射的细粒度控制
crush-compat方式调整其实就是调整权重其实就是使用了下方命令:
ceph osd crush weight-set reweight-compat 0 1.002479 ceph osd crush weight-set reweight-compat 1 0.998962 ceph osd crush weight-set reweight-compat 2 1.027126
2.使用balancer插件参考:http://docs.ceph.com/docs/luminous/mgr/balancer/ https://docs.ceph.com/en/latest/rados/operations/balancer/
balancer插件分为自动和手动两种,因为调整pg会引起数据迁移,所以使用手动调整保险些。更多详细说明,
2.1.检查是否启用了balancer插件balancer插件默认是开启的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 root@ceph-1:~ //返回 MODULE balancer on (always on) // 启用 crash on (always on) devicehealth on (always on) orchestrator on (always on) pg_autoscaler on (always on) progress on (always on) rbd_support on (always on) status on (always on) telemetry on (always on) volumes on (always on) cephadm on dashboard on iostat on nfs on prometheus on restful on alerts - ceph mgr module enable balancer ceph balancer status root@ceph-1:~ //返回 { "active" : true , "last_optimize_duration" : "0:00:00.003865" , "last_optimize_started" : "Mon Mar 6 06:27:11 2023" , "mode" : "upmap" , "optimize_result" : "Unable to find further optimization, or pool(s) pg_num is decreasing, or distribution is already perfect" , "plans" : [] }
NOTE:这里有两种方法调整,一个自动的,一个手动的,这个根据自己的掌握程度和方便程度进行调整,注意调整完了,把balancer进行关闭掉。
Ⅰ. 手动调整方式 2.2.开始手动调整pg分布1 2 3 4 ceph balancer off ceph balancer mode crush-compat
note:一共三种模式<upmap/crush-compat/none>
2.2.1.对当前PG分布进行评分 / balancer状态1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 root@ceph-1:~ current cluster score 0.000000 (lower is better) ceph balancer status //返回 { "active" : false , "last_optimize_duration" : "0:00:00.012473" , "last_optimize_started" : "Mon Mar 6 06:54:05 2023" , "mode" : "crush-compat" , "optimize_result" : "Distribution is already perfect" , "plans" : [] }
2.2.2.创建计划 待数据平衡之后,生成计划,以备以后使用(不用执行了解即可)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ceph balancer optimize <plan-name> {pool-name} ceph balancer optimize <plan_name> ceph balancer eval <plan_name> 注意:如果得到的评分比之前的低,说明这次调整是有效的,可以执行该计划,否则不需要执行该计划。 ceph balancer show <plan_name> ceph balancer execute <plan_name> 然后观察集群状态,此时会有数据迁移。然后可以通过ceph osd df 命令来查看pg分布情况,一般osd上包含的pg数最大和最小之间在5以内,算是比较均衡的。 ceph balancer show ls ceph balancer rm <plan_name>,或者全部清空ceph balancer reset
Ⅱ. 自动调整的方法 1.设置为crush-compat模式1 2 ceph balancer mode crush-compat
2.开启1 2 3 4 ceph balancer on ceph -w
3.用于辅助查看集群各个pool池PG在OSD 上的 分布情况脚本(pool池按序号)脚本参数参考:https://www.cnblogs.com/zphj1987/p/13575311.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #!/bin/bash ceph pg dump | awk ' /^PG_STAT/ { col=1; while($col!="UP") {col++}; col++ } /^[0-9a-f]+\.[0-9a-f]+/ { match($0,/^[0-9a-f]+/); pool=substr($0, RSTART, RLENGTH); poollist[pool]=0; up=$col; i=0; RSTART=0; RLENGTH=0; delete osds; while(match(up,/[0-9]+/)>0) { osds[++i]=substr(up,RSTART,RLENGTH); up = substr(up, RSTART+RLENGTH) } for(i in osds) {array[osds[i],pool]++; osdlist[osds[i]];} } END { printf("\n"); slen=asorti(poollist,newpoollist); printf("pool :\t");for (i=1;i<=slen;i++) {printf("%s\t", newpoollist[i])}; printf("| SUM \n"); for (i in poollist) printf("--------"); printf("----------------\n"); slen1=asorti(osdlist,newosdlist) delete poollist; for (j=1;j<=slen;j++) {maxpoolosd[j]=0}; for (j=1;j<=slen;j++) {for (i=1;i<=slen1;i++){if (array[newosdlist[i],newpoollist[j]] >0 ){minpoolosd[j]=array[newosdlist[i],newpoollist[j]] ;break } }}; for (i=1;i<=slen1;i++) { printf("osd.%i\t", newosdlist[i]); sum=0; for (j=1;j<=slen;j++) { printf("%i\t", array[newosdlist[i],newpoollist[j]]); sum+=array[newosdlist[i],newpoollist[j]]; poollist[j]+=array[newosdlist[i],newpoollist[j]];if(array[newosdlist[i],newpoollist[j]] != 0){poolhasid[j]+=1 };if(array[newosdlist[i],newpoollist[j]]>maxpoolosd[j]){maxpoolosd[j]=array[newosdlist[i],newpoollist[j]];maxosdid[j]=newosdlist[i]};if(array[newosdlist[i],newpoollist[j]] != 0){if(array[newosdlist[i],newpoollist[j]]<=minpoolosd[j]){minpoolosd[j]=array[newosdlist[i],newpoollist[j]];minosdid[j]=newosdlist[i]}}}; printf("| %i\n",sum)} for (i in poollist) printf("--------"); printf("----------------\n"); slen2=asorti(poollist,newpoollist); printf("SUM :\t"); for (i=1;i<=slen;i++) printf("%s\t",poollist[i]); printf("|\n"); printf("Osd :\t"); for (i=1;i<=slen;i++) printf("%s\t",poolhasid[i]); printf("|\n"); printf("AVE :\t"); for (i=1;i<=slen;i++) printf("%.2f\t",poollist[i]/poolhasid[i]); printf("|\n"); printf("Max :\t"); for (i=1;i<=slen;i++) printf("%s\t",maxpoolosd[i]); printf("|\n"); printf("Osdid :\t"); for (i=1;i<=slen;i++) printf("osd.%s\t",maxosdid[i]); printf("|\n"); printf("per:\t"); for (i=1;i<=slen;i++) printf("%.1f%\t",100*(maxpoolosd[i]-poollist[i]/poolhasid[i])/(poollist[i]/poolhasid[i])); printf("|\n"); for (i=1;i<=slen2;i++) printf("--------");printf("----------------\n"); printf("min :\t"); for (i=1;i<=slen;i++) printf("%s\t",minpoolosd[i]); printf("|\n"); printf("osdid :\t"); for (i=1;i<=slen;i++) printf("osd.%s\t",minosdid[i]); printf("|\n"); printf("per:\t"); for (i=1;i<=slen;i++) printf("%.1f%\t",100*(minpoolosd[i]-poollist[i]/poolhasid[i])/(poollist[i]/poolhasid[i])); printf("|\n"); }'
脚本输出
4.关闭方法(观察pg分布情况较为均衡时即可关闭)5. 调整的粒度默认的控制为5%,如果需要调整高或者低用下面的参数控制
1 2 ceph config-key set mgr/balancer/max_misplaced .03
6. 注意事项1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 3、相关配置修改: ceph config-key dump // 回显很长 截取其中重要部分配置如下 { "mgr/balancer/active" : "1" , "mgr/balancer/mode" : "crush-compat" , "mgr/balancer/sleep_interval" : "100" ,“mgr/balancer/begin_time”:”0000”, “mgr/balancer/end _time”:”2400”, } 参数解释: mgr/balancer/active:自动周期执行 mgr/balancer/mode: 模式 mgr/balancer/begin_time, mgr/balancer/end _time mgr/balancer/sleep_interval, (在配置的时间段执行的频率) ceph config-key set 例如: ceph config-key set "mgr/balancer/sleep_interval" "30" ceph orch restart mgr
三. upmap模式 参考
https://docs.ceph.com/en/latest/rados/operations/upmap/ https://blog.csdn.net/ff_gogo/article/details/87981682 https://ypdai.github.io/2020/07/30/osd%EF%BC%9Apg%E5%9D%87%E8%A1%A1%E5%B7%A5%E5%85%B7balancer/
upmap模式:
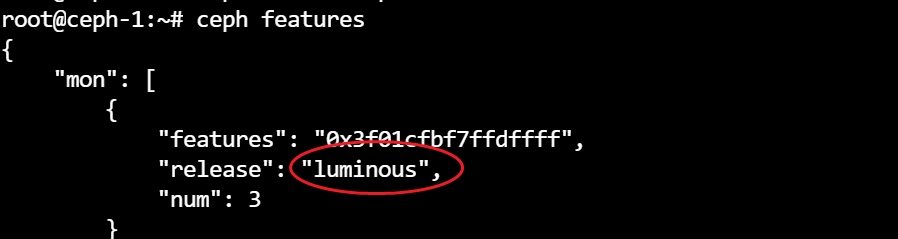
Upmap是Luminous版本新增功能,实现以pg单位重新映射特定的pg到特定的osd,实现方法是将更新的pg映射关系添加到osdmap中,以此实现对PG映射的细粒度控制,使用upmap模式的前提是集群中的所有服务以及客户端都要升级到Luminous版本及以上,即对于客户端来说,要能够理解osdmap中的pg-upmap-items表。可以通过ceph features命令查看当前集群版本,同时要使用ceph osd set-require-min-compat-client luminous进行设置。
可以通过osdmaptool工具来生成优化结果,官方文档建议针对每个pool进行pg均衡,当对所有pool执行了优化后,实际上就达成了集群均衡,默认的误差允许范围是1%。
环境 1 2 3 4 5 6 7 8 9 10 apt install ceph-base -y ceph balancer off ceph osd set-require-min-compat-client luminous root@ceph-1:~ set require_min_compat_client to luminousceph features
获取osdmap的最新副本 1 2 root@ceph-1:~ got osdmap epoch 971
运行优化器 (建议对单个pool池进行单独优化) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 osdmaptool om --upmap out.txt [--upmap-pool <pool>] \ [--upmap-max <max-optimizations>] \ [--upmap-deviation <max-deviation>] \ [--upmap-active] osdmaptool om --upmap out.txt --upmap-pool ceph-demo 回显: osdmaptool: osdmap file 'om' writing upmap command output to: out.txt checking for upmap cleanups upmap, max-count 10, max deviation 5 limiting to pools ceph-demo ([11]) pools ceph-demo prepared 0/10 changes Unable to find further optimization, or distribution is already perfect source out.txt // 无回显
执行上面脚本查看pg在osd上分布情况 参数说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ceph osd getmap -o osdmap osdmaptool om --upmap out.txt [--upmap-pool <pool>] \ [--upmap-max <max-optimizations>] \ [--upmap-deviation <max-deviation>] \ [--upmap-active] **条件说明: --upmap-pool : 指定多个pool,但它们是映射到相同设备和存储相同类型数据的池 --upmap-max <max-optimizations> : 默认为10, 运行中要标识的upmap条目的最大数量,如果进行离线优化,则值应该更大一点 --upmap-deviation <max-deviation> : 最大偏差值默认为5, 如果OSD PG计数与计算的目标数的差异应该小于或等于这个数量 --upmap-active : active的均衡器在upmap模式下的行为 它一直循环,直到OSD平衡,并报告多少轮以及每轮需要多长时间。循环所用的时间表示当它试图计算下一个优化计划时CPU负载ceph mgr将消耗的时间。 source out.txt在上面的示例中,建议的更改将写入输出文件out.txt。这些是正常的ceph CLI命令,可以运行这些命令将更改应用于集群。 可以根据需要重复上述步骤多次,以实现每组池的PG的完美分布。 通过向osdmaptol传递--debug osd 10,甚至更多的--debug crush 10,您可以看到该工具正在做什么的一些(糟糕的)细节。



 微信
微信








